The 90% Problem: Why GenAI Alone Can’t Solve Prior Authorization
GenAI can produce a solid first draft of policy reasoning extracts, but in prior authorization (PA) the remaining 10% error is a patient safety, compliance, and financial disaster. The fix is GenAI with evidence: a Human in the Loop (HITL) QA Sidecar—so every output is citable, auditable, and measurably correct.
The “90% is not good enough” reality
In prior authorization, a single determination often rests on many specific criteria (diagnosis, labs, time windows, step therapies, exclusions, prescriber specialty, quantities and renewal thresholds). Even if a model is “90% accurate”, the combined probability that all criteria are correct plummets:
- 10 criteria at 90% each → 0.910 ≈ 35% overall correctness.
- 15 criteria at 90% each → 0.915 ≈ 21% overall correctness.
Now flip the target: if you drive per-criterion accuracy to 99.9%, then 10-criterion decisions are 0.99910 ≈ 99.0% correct.
Why “pure GenAI” breaks in PA
- Narrative PDFs, not data. Policies are prose—time-boxed, exception-heavy, and plan-specific.
- No provenance. Free-text answers often lack line-level citations back to the exact clause.
- Non-determinism. Small prompt changes yield different outputs, making audits riskier. Strict regex will break too, because templates can be misformatted, contain misspellings, or a policy may not be self-contained.
- Hidden edge cases. Negative conditions (“not for…”, “unless…”) and nested logic (AND/OR) are easy to miss.
- Compounding error. Even “good” clause recall becomes unacceptable when multiplied across a full determination.
Conclusion: GenAI alone is a great first draft—and an unacceptable final decision system.
The solution: GenAI with Human-grade Verification
We pair GenAI with evidence and guardrails:
-
Gold Standard dataset (target 99.9% clause accuracy—like Clorox, we can’t claim 100%).
- Normalize and atomize each policy into clause-level “coverage atoms” (e.g.,
cnid_lab_a1c_ge_7_90d,cnid_step_any_two_orals_n2,cnid_specialist_endocrinology). - Provenance by design: every atom links to {plan, uid, pdf_url}.
- Versioned snapshots & drift: clause and CNID prevalence over time for each plan/drug/indication.
- Normalize and atomize each policy into clause-level “coverage atoms” (e.g.,
-
HITL QA Sidecar (the reviewer cockpit)
- Side-by-side view: model policy on the left; exact cited clauses on the right, with edit permissions.
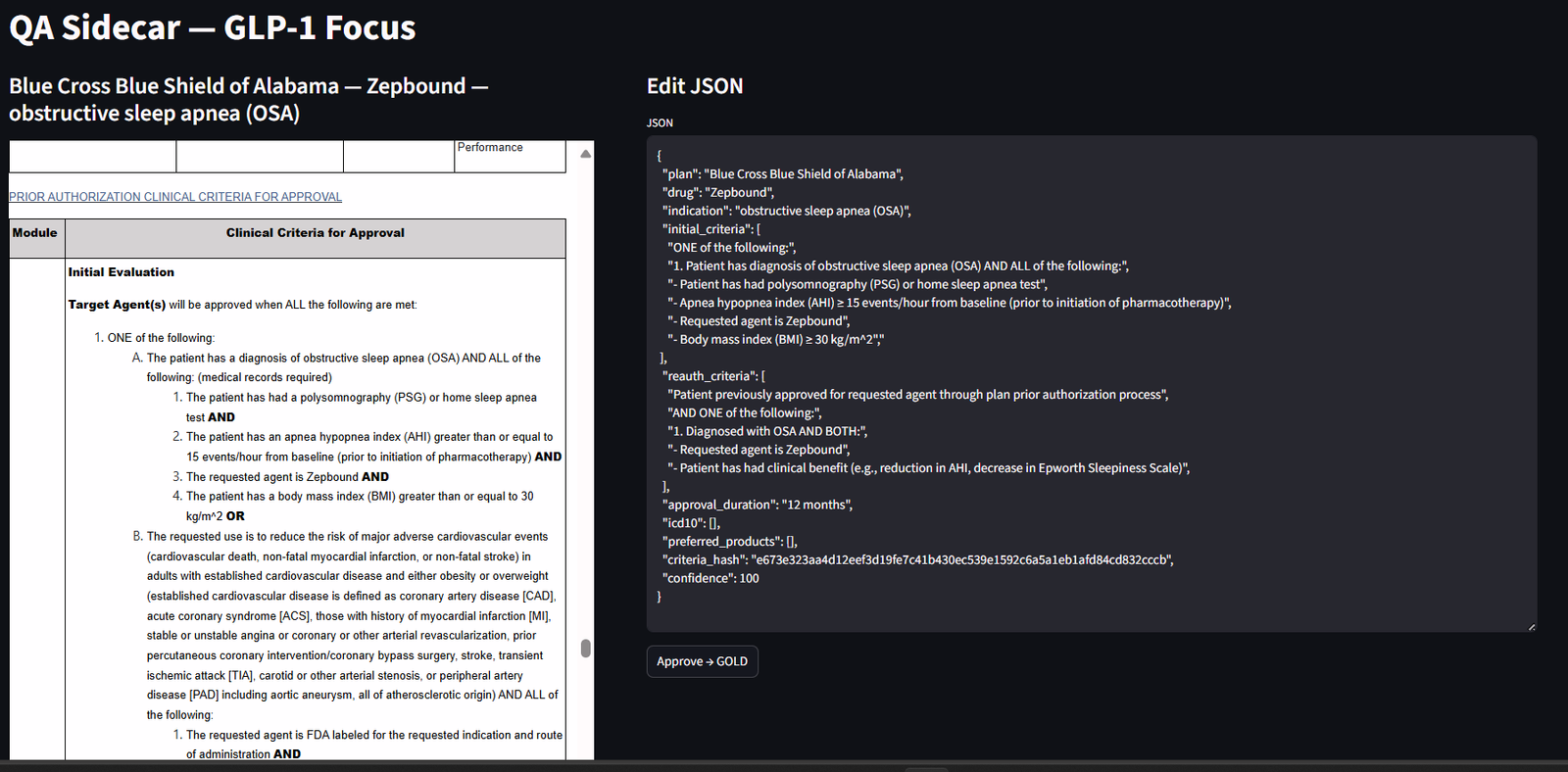
Figure 1 — HITL QA Sidecar (Streamlit). Left: model claims and structured fields (plan, drug, indication, CNIDs). Right: the exact cited clauses with {plan, uid, clause_id, pdf_url} and time windows highlighted. Reviewers accept or correct each field; approvals are versioned and hash logged. - Pass/fail rubric: reviewers check scope (plan/drug/indication), logic (AND/OR), thresholds (A1c ≥ 7), auth windows (≤ 90 days), ICD-10 codes, and renewal criteria.
- Structured outputs only: if a set of criteria doesn’t match, it can be sent back into an earlier phase of the data pipeline.
- One-click corrections: reviewers can swap in the correct clause; corrections are logged to improve future runs.
-
Small deterministic math on top
- Counts, ladders, prevalence: these can all be computed across plans, not guessed.
- Pre-Check bundles: Likely / Borderline / Unlikely CNIDs per plan-drug pairings are a future feature development.
- Doc Pack: auto-generated appeal packets and flags for unmet criteria.
Quality you can measure (and promise)
Auditability KPIs
- Traceability: every published claim retains {plan, uid, clause_id, statement_hash, pdf_url}.
- Snapshot integrity: criteria and clause hashes match the drug × plan × indication combination at first pass. Each answer is linked to a specific version.
A concrete example (GLP-1s)
Draft claim: “UHC requires two oral agent trials within 90 days and A1c ≥ 7% for initial approval for drug X; renewal requires ≥ 1% A1c reduction.”
Sidecar check items
- Step therapy atoms present?
cnid_step_any_two_orals_n2,window_days=90 - Lab threshold atom present?
cnid_lab_a1c_ge_7_90d - Renewal atom present?
cnid_renewal_a1c_drop_ge_1 - Scope correct? (GLP-1, adult T2D)
- Citations present? Show the exact UHC clause lines; verify no clause contradicts.
- Decision: Approve or request edit (e.g., step window is 120 days, not 90).
Outcome: The claim ships only if every atom is supported by a cited clause from the current snapshot. Otherwise, it is corrected or rejected.
Why this builds trust with clinicians, payers, and manufacturers
- No black boxes. Every claim is tied to line-level evidence and normalized into a deterministic schema.
- Deterministic “math”. Counts, restrictiveness ladders, prevalence, and pre-checks are computed from ground clinical truth, not guessed.
- Auditable by design. Hashes, timestamps, and snapshot versioning make compliance and root-cause analysis straightforward. Hash-awareness and idempotency are critical facets of provenance.
- Human-grade standards. The Sidecar enforces a repeatable QA rubric so “90% drafts” become “99%+ decisions.”
Call to action
See it live: Request a 10-minute walkthrough of the HITL QA Sidecar (we’ll review a GLP-1 example end to end).
The button above creates an email to pharmularyproject@gmail.com with the subject pre-filled.
Bottom line: GenAI gets you a fast, credible first draft. In prior authorization, safety and compliance demand evidence, grammar, and humans—so accuracy compounds and trust is earned.